וזה לא עניין טכני קטן. זו החלטה עסקית שמשפיעה על זמן, כסף, אמינות, תחזוקה, ואמון של עובדים ולקוחות. כשמנהלים שומעים “צריך AI שמכיר את החברה”, הרבה פעמים המחשבה הראשונה היא Fine-tuning. כלומר, לקחת מודל קיים ולאמן אותו על מידע או דוגמאות שלכם. אבל בהרבה מקרים, מה שבאמת צריך הוא RAG: חיבור של המודל למסמכים, מאגרי ידע ומקורות עדכניים, כדי שיוכל לשלוף מהם מידע בזמן המענה.
ההבדל הפשוט הוא כזה: RAG עוזר למודל לדעת על מה לענות. Fine-tuning עוזר למודל ללמוד איך להתנהג.
אם אתם רוצים שהמודל יענה לפי נהלים, יצטט מסמך, יתבסס על קטלוג מוצרים, או יתעדכן כשמשתנה מחירון, בדרך כלל תתחילו מ-RAG. אם אתם רוצים שהמודל יכתוב תמיד בסגנון מסוים, יסווג פניות באופן עקבי, או יבצע משימה צרה עם דפוס קבוע, Fine-tuning יכול להיות הכיוון.
הפרק הזה הוא עץ החלטה עסקי. לא נכנסים לעומק המתמטי, אלא לשאלה החשובה: מתי כל גישה מנצחת, ואיך לא לבזבז שבועות על אימון כשכל מה שהיה צריך הוא לחבר את המודל לידע הנכון.
האם אתם מנסים להוסיף ידע, או לשנות התנהגות?
זו השאלה הראשונה.
RAG, לפי מקור 2, הוא שיטה שבה מודלי שפה גדולים שולפים מידע ממקורות חיצוניים ומשלבים אותו בתשובה. המודל קודם ניגש לקבוצת מסמכים מוגדרת, ואז עונה לשאלה של המשתמש. המסמכים האלה משלימים את הידע שכבר היה למודל בזמן האימון המקורי שלו.
Fine-tuning, לפי מקור 1, הוא תהליך שבו לוקחים מודל שכבר אומן למשימה אחת, ומתאימים אותו למשימה אחרת, בדרך כלל ספציפית יותר. עושים זאת באמצעות אימון נוסף על הפרמטרים של רשת עצבית שכבר אומנה.
במילים של עבודה יומיומית:
אם הבעיה היא “המודל לא יודע את נוהל ההחזרים שלנו”, זו בעיית ידע.
אם הבעיה היא “המודל יודע את החומר, אבל עונה בטון לא מתאים או לא מסווג נכון פניות”, זו בעיית התנהגות.
דוגמה מעשית: חברת SaaS ישראלית רוצה צ'אט פנימי לצוות המכירות. אנשי המכירות שואלים: “מה ההבדל בין חבילת Pro לחבילת Enterprise?”, “מה מותר להבטיח ללקוח?”, “מה השתנה בהסכם השירות האחרון?”. אלה שאלות ידע. הידע נמצא במסמכים, מצגות, חוזים, דפי מוצר והנחיות. כאן RAG מתאים, כי הוא מאפשר למודל לשלוף מידע מתוך מקורות החברה ולענות על בסיסם.
לעומת זאת, נניח שמוקד שירות רוצה שהמודל יקרא פנייה ויחזיר תמיד אחת מחמש קטגוריות, בניסוח קבוע ובמבנה קבוע. אם יש לכם הרבה דוגמאות של פניות וקטגוריות נכונות, Fine-tuning יכול לעזור להפוך את ההתנהגות הזו לעקבית יותר.
הטעות הנפוצה היא לערבב בין השניים. עסק אומר: “המודל לא מכיר את החומרים שלנו, אז נאמן אותו”. אבל אם החומרים משתנים, אם צריך לצטט, ואם המשתמשים צריכים לבדוק את המקור, אימון אינו התחלה טובה. עדיף לחבר ידע.
לפי מקור 2, RAG מאפשר למודלים להשתמש במידע תחומי או מעודכן שאינו זמין בנתוני האימון. הוא גם מצמצם את הצורך לאמן מחדש מודלים עם מידע חדש, וכך חוסך בעלויות חישוביות וכספיות. Ars Technica, כפי שמובא במקור 2, מסביר שכאשר מידע חדש זמין, במקום לאמן את המודל מחדש, מעדכנים את בסיס הידע החיצוני.
זה קריטי לעסקים. מחירונים משתנים. תקנונים משתנים. מדיניות פרטיות משתנה. מסמכי מכרז משתנים. תסריטי מכירה משתנים. אם בכל שינוי כזה צריך לאמן מחדש מודל, יצרתם תהליך כבד מדי.
ב-RAG, השינוי העיקרי הוא במסמכים שהמודל ניגש אליהם. העליתם מסמך חדש, החלפתם נוהל, הוספתם מקור, והמודל יכול להשתמש במידע המעודכן בזמן המענה. זה לא אומר שהכול אוטומטית נכון. אבל זה הופך את תחזוקת הידע לברורה יותר: מנהלים ידע במסמכים, ולא בתוך משקולות של מודל.
דוגמה: רשת קמעונאית מפעילה עוזר AI לצוותי סניפים. בכל חודש משתנים מבצעים, תנאי החזרה והנחיות מלאי. אם מאמנים מודל על המידע הזה, כל שינוי מעלה שאלה: האם צריך אימון נוסף? האם המודל זוכר גם גרסאות ישנות? האם התשובה ניתנת לבדיקה? ב-RAG, אפשר לכוון את המודל למסמכים הנוכחיים ולבקש ממנו לציין מאיזה נוהל הוא ענה.
Fine-tuning מתאים פחות כאשר מרכז הכובד הוא מידע חי. הוא יכול להתאים כאשר המשימה עצמה יציבה. למשל, זיהוי סוג פנייה, כתיבה במבנה קבוע, או התאמת סגנון. אם ההתנהגות שאתם רוצים כמעט לא משתנה, והדוגמאות שלכם מייצגות היטב את המשימה, Fine-tuning יכול להיות מועיל.
עץ ההחלטה כאן פשוט: אם אתם שואלים “איך נעדכן את המודל בכל פעם שהחומר משתנה?”, עצרו. כנראה שאתם צריכים RAG לפני Fine-tuning.
האם המשתמשים צריכים לראות מקור או ציטוט?
אם התשובה צריכה להיות ניתנת לבדיקה, RAG בדרך כלל מנצח.
לפי מקור 2, RAG מאפשר למודלים לכלול מקורות בתשובות, כדי שהמשתמשים יוכלו לבדוק את המקורות שצוטטו. זה נותן שקיפות גבוהה יותר, כי המשתמשים יכולים לוודא שהתוכן שנשלף מדויק ורלוונטי.
בעסקים, זה ההבדל בין תשובה שנשמעת טוב לבין תשובה שאפשר לעבוד איתה. מנהל כספים, יועצת משפטית, מנהלת משאבי אנוש או סמנכ"ל מכירות לא צריכים רק טקסט יפה. הם צריכים לדעת: על מה זה מבוסס?
דוגמה: מנהלת משאבי אנוש שואלת את העוזר הארגוני: “כמה ימי חופשה מגיעים לעובד לפי הנוהל הפנימי שלנו אחרי שנתיים?”. תשובה בלי מקור עלולה להישמע בטוחה ועדיין להיות מסוכנת. אם המודל מציג גם את המסמך שממנו הוא ענה, אפשר לפתוח אותו ולבדוק. זו נקודה עסקית, לא רק טכנית.
Fine-tuning לא בנוי סביב שליפה וציטוט של מקור בזמן המענה. הוא משנה את המודל עצמו דרך אימון נוסף. לכן, גם אם המודל למד דפוס מסוים, הוא לא בהכרח יכול להראות לכם מאיזה מסמך הגיעה תשובה ספציפית. אם אתם צריכים עקיבות, RAG מתאים יותר.
חשוב לדייק: RAG לא מבטל טעויות. מקור 2 מציין שמודלים יכולים לייצר מידע שגוי גם כשהם שולפים ממקורות נכונים, אם הם מפרשים את ההקשר לא נכון. הדוגמה שמובאת שם היא תשובה שגויה שנוצרה בעקבות פירוש לא נכון של כותרת ספר אקדמי. כלומר, RAG משפר את המצב, אבל עדיין צריך לבדוק איך המערכת מציגה מקורות, איך היא מטפלת באי ודאות, ואיך היא נמנעת מקפיצה למסקנות.
לכן, בעץ ההחלטה: אם המשתמש שואל “איפה זה כתוב?”, בנו סביב RAG. אם המשתמש שואל “למה המודל לא מתנהג באותו אופן בכל פעם?”, בדקו Fine-tuning.
האם הבעיה היא הזיות, או חוסר משמעת?
הרבה מנהלים משתמשים במילה “הזיות” לכל תשובה גרועה של AI. אבל לא כל שגיאה היא אותה שגיאה.
מקור 2 מסביר ש-RAG עוזר להפחית הזיות, משום שהוא משלב שליפת מידע לפני יצירת התשובה. לפי Ars Technica, כפי שמובא במקור 2, RAG משלב את תהליך המודל עם חיפוש באינטרנט או בדיקת מסמכים כדי לעזור למודל להיצמד לעובדות. מקור 2 גם מזכיר שמודלים עלולים להמציא מדיניות שלא קיימת או להמליץ על תקדימים משפטיים לא קיימים לעורכי דין שמחפשים ציטוטים.
אם המודל ממציא עובדות, נהלים, שמות מסמכים, פרטי מוצר או סעיפים, צריך לתת לו מקור חיצוני ברור. כאן RAG הוא התשובה הראשונה שצריך לבדוק.
אבל יש סוג אחר של בעיה: המודל לא ממושמע. הוא מאריך מדי, משנה פורמט, לא שומר על טון, לא מסווג בדיוק, או לא מחזיר את אותם שדות. זו לא תמיד בעיית ידע. לפעמים זו בעיית התנהגות.
דוגמה: צוות שיווק רוצה שהמודל יכתוב תקצירי קמפיינים במבנה קבוע: קהל יעד, הצעה, ערוץ, מסר מרכזי, סיכון. אם המודל יודע את המידע אבל כל פעם מחזיר מבנה אחר, RAG לא בהכרח יספיק. אפשר לשפר הרבה בעזרת הנחיות טובות ודוגמאות בפרומפט, אבל אם המשימה חוזרת הרבה ויש דוגמאות איכותיות, Fine-tuning עשוי להתאים.
לפי מקור 1, Fine-tuning הוא צורה של transfer learning: שימוש חוזר בידע שנלמד באימון המקורי והתאמתו למשימה ספציפית יותר. זה בדיוק המקום שבו הוא חזק. לא כדי להפוך את המודל לארכיון החברה, אלא כדי ללמד אותו לבצע סוג מסוים של פעולה בצורה עקבית יותר.
אז שאלו כך: האם המודל טועה כי חסר לו חומר, או כי הוא לא מבצע את המשימה כמו שאתם רוצים? אם חסר חומר, RAG. אם ההתנהגות עצמה לא מתאימה, Fine-tuning.
האם יש לכם דוגמאות איכותיות לאימון?
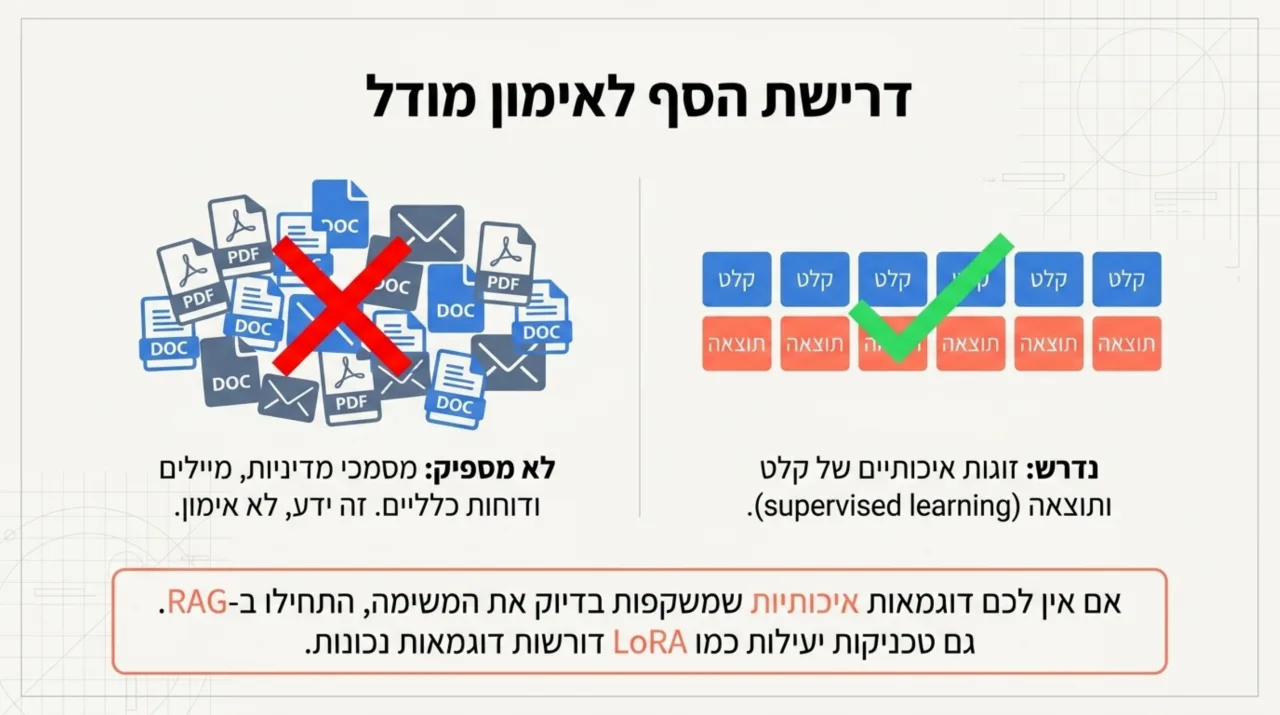
Fine-tuning דורש דוגמאות. לא רק “יש לנו הרבה מידע”, אלא דוגמאות שמראות למודל איך נראית התנהגות נכונה.
מקור 1 מציין ש-Fine-tuning נעשה בדרך כלל באמצעות supervised learning, כלומר אימון עם דוגמאות שבהן יש קלט ותוצאה רצויה. יש גם טכניקות שמשתמשות ב-weak supervision, אבל הנקודה העסקית נשארת: צריך חומר שמייצג היטב את המשימה.
כאן הרבה פרויקטים נתקעים. לחברה יש מסמכי מדיניות, מצגות, מיילים, דוחות, סיכומי פגישות ומאמרים פנימיים. אבל אלה לא בהכרח דוגמאות אימון טובות. מסמך הוא ידע. דוגמת אימון היא זוג של “כך שואלים” ו-“כך צריך לענות”, או “כך נראית פנייה” ו-“זו הקטגוריה הנכונה”.
דוגמה: אם אתם רוצים לאמן מודל שמסווג פניות לקוחות, תצטרכו דוגמאות של פניות מסווגות נכון. אם אתם רוצים לאמן מודל שכותב תשובות שירות בסגנון החברה, תצטרכו דוגמאות של שאלות ותשובות טובות. אם יש לכם רק נהלי שירות, ייתכן ש-RAG מתאים יותר בהתחלה, כי המודל יכול לשלוף את הנוהל ולנסח תשובה על בסיסו.
עוד נקודה ממקור 1: Fine-tuning יכול להתבצע על כל הרשת, או רק על חלק מהשכבות, כאשר שכבות אחרות “קפואות” ולא משתנות. יש גם adapters, שהם רכיבים קלים יותר שמוכנסים לארכיטקטורה ומאפשרים התאמה עם פחות פרמטרים מהמודל המקורי. LoRA, לפי מקור 1, היא טכניקה מבוססת adapters שמאפשרת לבצע Fine-tuning ביעילות גבוהה יותר מבחינת מקום, ובמודל שפה עם מיליארדי פרמטרים אפשר לבצע LoRA fine-tuning עם כמה מיליוני פרמטרים בלבד.
אבל גם אם הטכניקה יעילה יותר, היא לא פוטרת אתכם מהשאלה העסקית: האם יש לכם דוגמאות נכונות? אם אין, אל תקפצו לאימון. התחילו ב-RAG, בהנחיות טובות, ובבדיקה ידנית של דוגמאות שימוש אמיתיות.
האם אתם צריכים סגנון קבוע, או תשובה מבוססת מסמך?
זו אחת ההבחנות הכי מועילות בשטח.
RAG עונה טוב על “מה כתוב אצלנו?”. Fine-tuning עונה טוב יותר על “איך אנחנו רוצים שהמודל יפעל?”.
נניח שיש לכם משרד ייעוץ. אתם רוצים עוזר AI שכותב הצעות ללקוחות. יש כאן שני צרכים שונים. הראשון הוא ידע: אילו שירותים אתם מציעים, מה הניסיון שלכם, אילו פרויקטים עשיתם, מה מותר להבטיח, מה המחירים או המסגרות. זה מתאים ל-RAG, כי המידע נמצא במסמכים וצריך להישאר מעודכן.
הצורך השני הוא סגנון: איך נראית הצעה שלכם, באיזה סדר מופיעים חלקים, באיזה טון כותבים, כמה לפרט, מתי להכניס הסתייגות. כאן Fine-tuning יכול להיות רלוונטי אם יש לכם מספיק דוגמאות טובות של הצעות קיימות והתנהגות רצויה.
בפועל, בהרבה ארגונים הבחירה אינה או-או. אפשר להשתמש ב-RAG כדי להביא את הידע הנכון, וב-Fine-tuning כדי לעצב התנהגות עקבית. אבל הסדר חשוב. אם הבעיה הבוערת היא שהמודל לא מכיר את החומר, אל תתחילו באימון. קודם חברו את הידע. אחר כך בדקו אם עדיין יש בעיית סגנון או משמעת.
מקור 2 מציין שבשלב היצירה, לפי IBM כפי שמובא שם, המודל משתמש בפרומפט המועשר ובייצוג הפנימי שלו מנתוני האימון כדי להרכיב תשובה. זה אומר שגם ב-RAG המודל עדיין מנסח, מסכם ומחבר. לכן צריך להגדיר לו איך לענות. אבל מקור הידע החיצוני הוא מה שמאפשר לו להתבסס על מסמכים רלוונטיים במקום להישען רק על מה שהיה באימון המקורי.
הכלל העסקי: אם המנהל צריך לבדוק את התוכן מול מסמך, RAG. אם המנהל כבר יודע שהתוכן נכון אבל רוצה פלט קבוע ואחיד יותר, Fine-tuning.
מה הסיכון אם בוחרים לא נכון?
הסיכון הראשון הוא תחזוקה. אם מאמנים מודל על מידע שמשתנה, אתם עלולים ליצור תלות בתהליך עדכון כבד. במקום לעדכן מסמך, צריך לחשוב על אימון נוסף, בדיקות, השוואות ובקרת איכות.
הסיכון השני הוא אמינות. אם משתמשים ב-Fine-tuning במקום RAG עבור ידע ארגוני, קשה יותר להסביר למשתמש מאיפה הגיעה תשובה. במקומות שבהם צריך מקור, זה פוגע באמון.
הסיכון השלישי הוא ביטחון יתר. מודל יכול לענות בביטחון גם כשהוא טועה. מקור 2 מזכיר את ההדגמה הראשונה של Google Bard, שהפך בהמשך ל-Gemini, שבה נמסר מידע שגוי על James Webb Space Telescope. לפי מקור 2, הטעות תרמה לירידה של 100 מיליארד דולר בשווי המניה של Google. זה מקרה קיצוני, אבל הוא מדגים נקודה פשוטה: תשובה שגויה של מודל אינה רק תקלה טכנית. לפעמים היא אירוע עסקי.
הסיכון הרביעי הוא אובדן יכולת כללית. מקור 1 מציין ש-Fine-tuning יכול לפגוע בעמידות של מודל לשינויים בהתפלגות הנתונים. כלומר, מודל שהותאם למשימה מסוימת עלול להתנהג פחות טוב כשהקלט שונה ממה שראה בתהליך ההתאמה. מקור 1 גם מציין דרך התמודדות אחת: שילוב ליניארי של משקולות המודל שעבר Fine-tuning עם משקולות המודל המקורי, שיכול לשפר ביצועים מחוץ להתפלגות תוך שמירה רחבה על ביצועים בתוך ההתפלגות.
לא צריך להיבהל מזה, אבל כן צריך להבין: Fine-tuning אינו כפתור קסם. הוא משנה את המודל. שינוי כזה דורש בדיקות. צריך לבדוק לא רק את הדוגמאות שבהן רציתם שיפור, אלא גם מקרים קרובים, מקרים חריגים ושאלות שהמודל כבר ידע לענות עליהן לפני כן.
RAG גם אינו חסין. מקור 2 מדגיש שהוא לא פותר את כל הבעיות. המודל יכול לפרש מקור נכון בצורה לא נכונה. לכן גם RAG צריך בדיקות: האם המסמך הנכון נשלף? האם הקטע שנשלף רלוונטי? האם התשובה נאמנה לקטע? האם הציטוטים עוזרים למשתמש לבדוק?
איך נראה עץ החלטה פשוט למנהל?
אפשר להפוך את כל זה לשאלון קצר.
שאלה ראשונה: האם התשובה צריכה להתבסס על מסמכים, נהלים, מאגרי ידע או מקורות חיצוניים?
אם כן, התחילו ב-RAG.
שאלה שנייה: האם המידע משתנה לעיתים קרובות?
אם כן, RAG מתאים במיוחד, כי לפי מקור 2 אפשר לעדכן את בסיס הידע החיצוני במקום לאמן מחדש את המודל בכל שינוי.
שאלה שלישית: האם המשתמשים צריכים לראות מקורות או לבדוק ציטוטים?
אם כן, RAG הוא הכיוון הנכון, כי הוא מאפשר לכלול מקורות בתשובות.
שאלה רביעית: האם הבעיה המרכזית היא שהמודל לא שומר על סגנון, מבנה, קטגוריות או דרך פעולה קבועה?
אם כן, בדקו Fine-tuning, במיוחד אם יש לכם דוגמאות איכותיות של קלט ותוצאה רצויה.
שאלה חמישית: האם יש לכם מספיק דוגמאות טובות לאימון, ולא רק מסמכים כלליים?
אם לא, אל תתחילו ב-Fine-tuning. אספו דוגמאות, שפרו הנחיות, ובדקו RAG.
שאלה שישית: האם אפשר להתחיל קטן?
כמעט תמיד כן. בחרו תרחיש אחד. למשל: עוזר למענה על שאלות פנימיות מתוך נהלי החברה, או מסווג פניות שירות. אל תנסו לבנות בבת אחת מערכת שיודעת הכול, כותבת הכול ומחליפה את כל תהליכי הידע בארגון.
הדרך הנקייה היא להגדיר את סוג הבעיה לפני שבוחרים טכנולוגיה. ידע ועדכניות, RAG. התנהגות וסגנון, Fine-tuning. שני הצרכים יחד, משלבים, אבל לא מערבבים.
איפה מתחילים בלי להסתבך?
התחלה טובה היא לא “איזה מודל נאמן?”, אלא “איזה שימוש אחד יחסוך זמן כבר החודש?”.
בחרו תהליך שבו אנשים שואלים שוב ושוב שאלות על אותו חומר. לדוגמה: נהלי משאבי אנוש, תיעוד מוצר, הוראות מכירה, שאלות תמיכה, מסמכי onboarding. אם החומר כבר כתוב, RAG הוא ניסוי טבעי. מחברים את המסמכים, מגדירים איך לענות, דורשים מקור, ובודקים תשובות מול שאלות אמיתיות.
אחר כך מודדים איכות בצורה פשוטה: האם נשלף המסמך הנכון? האם התשובה נאמנה למסמך? האם המשתמש מבין מה לעשות? האם יש מקור שאפשר לפתוח? אין צורך להמציא מדדים מורכבים בשלב הראשון. מספיק לקחת רשימת שאלות אמיתיות ולבדוק אותן אחת אחת.
אם אחרי זה רואים שהמידע נכון אבל ההתנהגות לא עקבית, זה הרגע לשקול Fine-tuning. למשל, המודל תמיד מוצא את הנוהל הנכון, אבל התשובות ארוכות מדי, לא בפורמט הנדרש, או לא שומרות על סגנון החברה. אז אפשר להתחיל לאסוף דוגמאות טובות: שאלה, הקשר, תשובה רצויה.
הגישה הזו חוסכת הרבה רעש. במקום להתווכח תאורטית על Fine-tuning מול RAG, נותנים לסוג הכאב להוביל. כאב של ידע, חיבור ידע. כאב של התנהגות, התאמת התנהגות.
מה כדאי לעשות עם זה השבוע
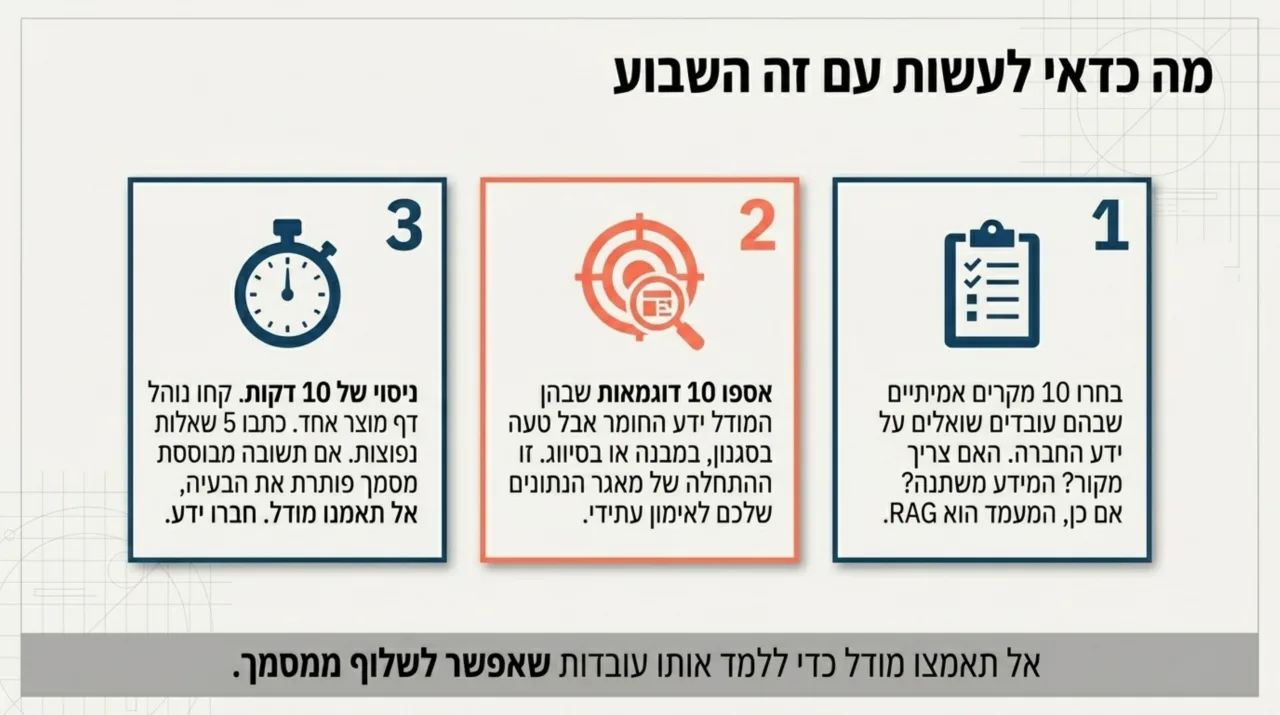
1. בחרו עשרה מקרים אמיתיים שבהם עובדים שואלים AI על ידע של החברה. ליד כל מקרה כתבו: האם צריך מקור? האם המידע משתנה? האם התשובה נמצאת במסמך קיים? אם רוב התשובות הן כן, זה מועמד ל-RAG.
2. אספו עשר דוגמאות שבהן המודל ידע את המידע אבל ענה לא כמו שרציתם. בדקו אם הבעיה היא סגנון, מבנה, סיווג או עקביות. אם כן, התחילו לבנות אוסף דוגמאות איכותי ל-Fine-tuning עתידי.
3. עשו ניסוי של 10 דקות: קחו מסמך אחד מרכזי, למשל נוהל, דף מוצר או מדריך שירות. כתבו חמש שאלות שעובדים באמת שואלים עליו. בדקו אם תשובה שמבוססת על המסמך, עם הפניה למקור, הייתה מספיקה. אם כן, אתם קרובים יותר ל-RAG מאשר לאימון.
השורה התחתונה של תכלס AI
מכירים מישהו שבנה אפליקציה ב-Lovable או Bolt?
שתפו אותם לפני שהם ממשיכים לשלם ולחכות שגוגל ימצא אותם
Fine-tuning ו-RAG לא מתחרים על אותו תפקיד. RAG מחבר את המודל לידע חיצוני, עדכני וניתן לבדיקה. Fine-tuning מתאים את ההתנהגות של מודל למשימה ספציפית יותר.
אם אתם צריכים תשובות שמבוססות על מסמכים, מקורות, נהלים או מידע שמשתנה, התחילו ב-RAG. אם אתם צריכים שהמודל יתנהג באופן עקבי, יכתוב בסגנון קבוע או יבצע משימה צרה עם דוגמאות ברורות, בדקו Fine-tuning.
הכלל הכי שימושי למנהל: אל תאמצו מודל כדי ללמד אותו עובדות שאפשר לשלוף ממסמך. חברו את הידע. את האימון שמרו למקרים שבהם באמת צריך לשנות את הדרך שבה המודל עובד.